Table Sampling
Use TABLESAMPLE in Phoenix for Bernoulli-style sampling, with performance notes, repeatability behavior, and tuning guidance.
To support table sampling (similar to PostgreSQL and T-SQL syntax), a TABLESAMPLE clause was incorporated into aliased table references as of Phoenix 4.12. The general syntax is described here. This feature limits the number of rows returned from a table to a percentage of rows. See PHOENIX-153 for implementation details.
This feature is implemented with a Bernoulli trial and a consistent-hashing-based table sampler to achieve Bernoulli sampling on a given row population. Given a sampling rate, it leverages Phoenix statistics and HBase region distribution to perform table sampling.
As part of statistics collection, a guidepost (a row reference) is created at equidistant byte intervals. When sampling is required, a Bernoulli trial process is applied repeatedly on each guidepost in each region with a probability proportional to the sampling rate. An included guidepost results in all rows between it and the next guidepost being included in the sample population.
Performance
Sampling on a table with a sampling rate of 100% costs roughly the same computational resources as a query without sampling.
Resource consumption drops quickly as sampling rate decreases. In general, the amortized complexity of the sampling process is O(k + mn), where:
nis the number of regions in the sampled HBase table.mis the number of guideposts.kis the sampled population size.
Repeatable
Repeatable means repeated sampling on the same table returns the same sampled result.
Repeatability is enabled by applying a consistent-hashing process to the binary representation of the start row key of each guidepost in each region during sampling. By default, an FNV1 implementation with lazy modulo is used. See FNV1.
Examples
To sample a table, execute a query such as the following. The sampling rate is a numeric value between 0 and 100, inclusive.
SELECT * FROM PERSON TABLESAMPLE (12.08);More examples:
SELECT * FROM PERSON TABLESAMPLE (12.08) WHERE ADDRESS = 'CA' OR NAME > 'aaa';
SELECT COUNT(*) FROM PERSON TABLESAMPLE (12.08) LIMIT 2;
SELECT COUNT(*) FROM (SELECT NAME FROM PERSON TABLESAMPLE (49) LIMIT 20);
SELECT * FROM (SELECT /*+ NO_INDEX */ * FROM PERSON TABLESAMPLE (10) WHERE NAME > 'tina10') WHERE ADDRESS = 'CA';
SELECT * FROM PERSON1, PERSON2 TABLESAMPLE (70) WHERE PERSON1.NAME = PERSON2.NAME;
SELECT /*+ NO_INDEX */ COUNT(*) FROM PERSON TABLESAMPLE (19), US_POPULATION TABLESAMPLE (28) WHERE PERSON.NAME > US_POPULATION.STATE;
UPSERT INTO PERSONBIG (ID, ADDRESS) SELECT ID, ADDRESS FROM PERSONBIG TABLESAMPLE (1);To use with aggregation:
SELECT COUNT(*) FROM PERSON TABLESAMPLE (49) LIMIT 2;
SELECT COUNT(*) FROM (SELECT NAME FROM PERSON TABLESAMPLE (49) LIMIT 20);To explain a sampled query:
EXPLAIN SELECT COUNT(*) FROM PERSON TABLESAMPLE (49) LIMIT 2;Tuning
- Due to the sampling process,
TABLESAMPLEshould be used with caution. For example, a join of two tables is likely to return a match for each row in both tables; however, when sampling is applied to one or both tables, join results may differ from non-sampled expectations. - Statistics should be collected to achieve the best sampling accuracy. To turn on statistics collection, refer to Statistics Collection.
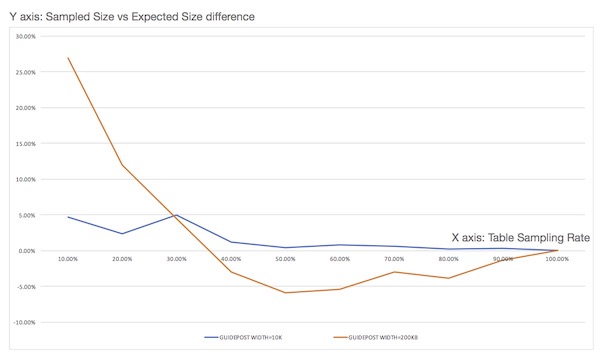
ALTER TABLE my_table SET GUIDE_POSTS_WIDTH = 10000000;- A denser guidepost setting improves sampling accuracy, but may reduce performance. A comparison is shown below.